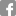Deep Learning

Deep learning is a powerful machine learning framework that has shown outstanding performance in many fields. The main power of deep learning comes from learning data representations directly from data in a hierarchical layer-based structure.
We apply deep learning to computer vision, autonomous driving, biomedicine, time series data, language, and other fields, and develop novel methods. Among the advanced methods we use and develop are uncertainty quantification, processing of advanced data structures (sequences, graphs, geometry, high-dimensional data), probabilistic graphical models, reinforcement learning, active learning, domain adaptation, anomaly detection, convolutional networks, recurrent networks, and causality inference.
Some of the works from our chair include: FlowNet, FuseNet, DVSO
Contact






Related publications
Export as PDF, XML, TEX or BIB
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2024
Journal Articles
[] 
Multi-vehicle trajectory prediction and control at intersections using state and intention information , In Neurocomputing, Elsevier, 2024. ([link][project page][code][pre-print])
Preprints
[] Uncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations , In arXiv preprint, 2024.
Conference and Workshop Papers
[] 
Sparse Views, Near Light: A Practical Paradigm for Uncalibrated Point-light Photometric Stereo , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. ([supp])
[] 
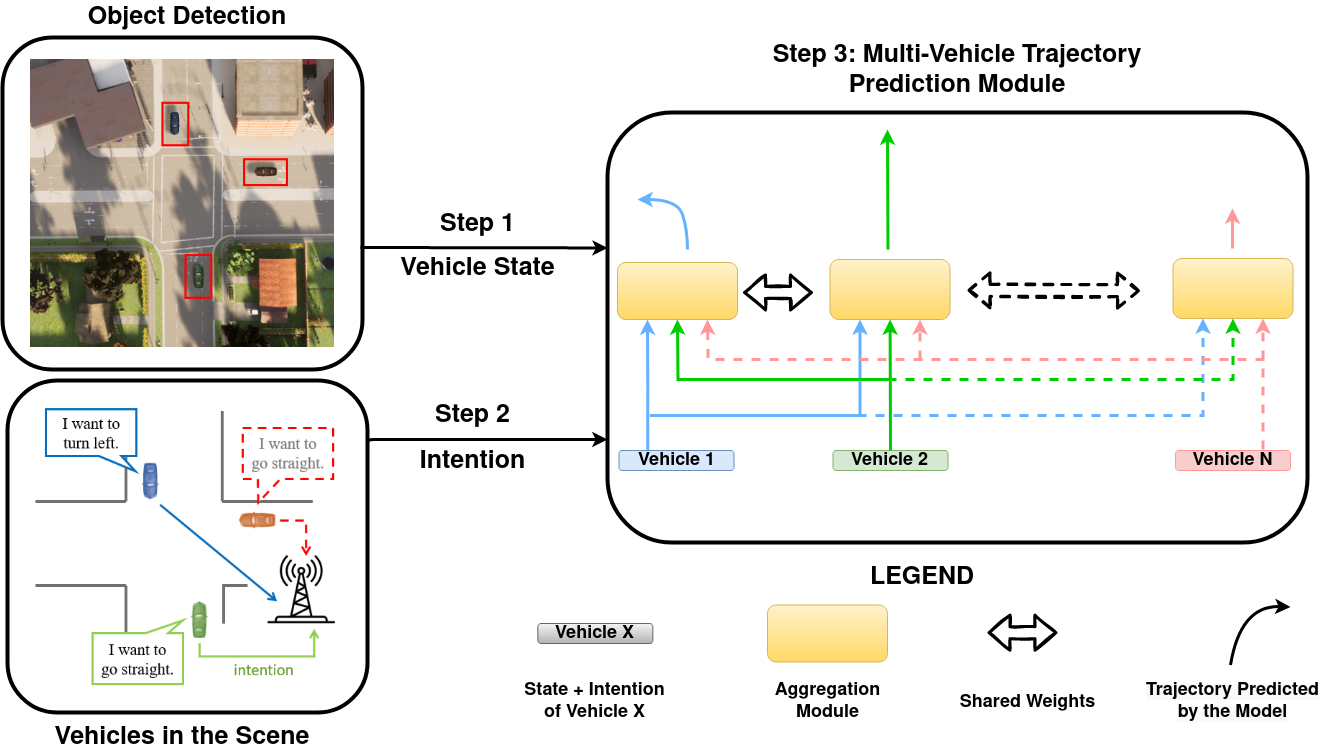
Enhancing Multimodal Compositional Reasoning of Visual Language Models with Generative Negative Mining , In IEEE Winter Conference on Applications of Computer Vision (WACV, 2024. ([arXiv][project page][code])
[] Text2Loc: 3D Point Cloud Localization from Natural Language , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. ([project page])
[] 
SupeRVol: Super-Resolution Shape and Reflectance Estimation in Inverse Volume Rendering , In IEEE Winter Conference on Applications of Computer Vision (WACV), 2024. ([supp])
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2023
Journal Articles
[] 
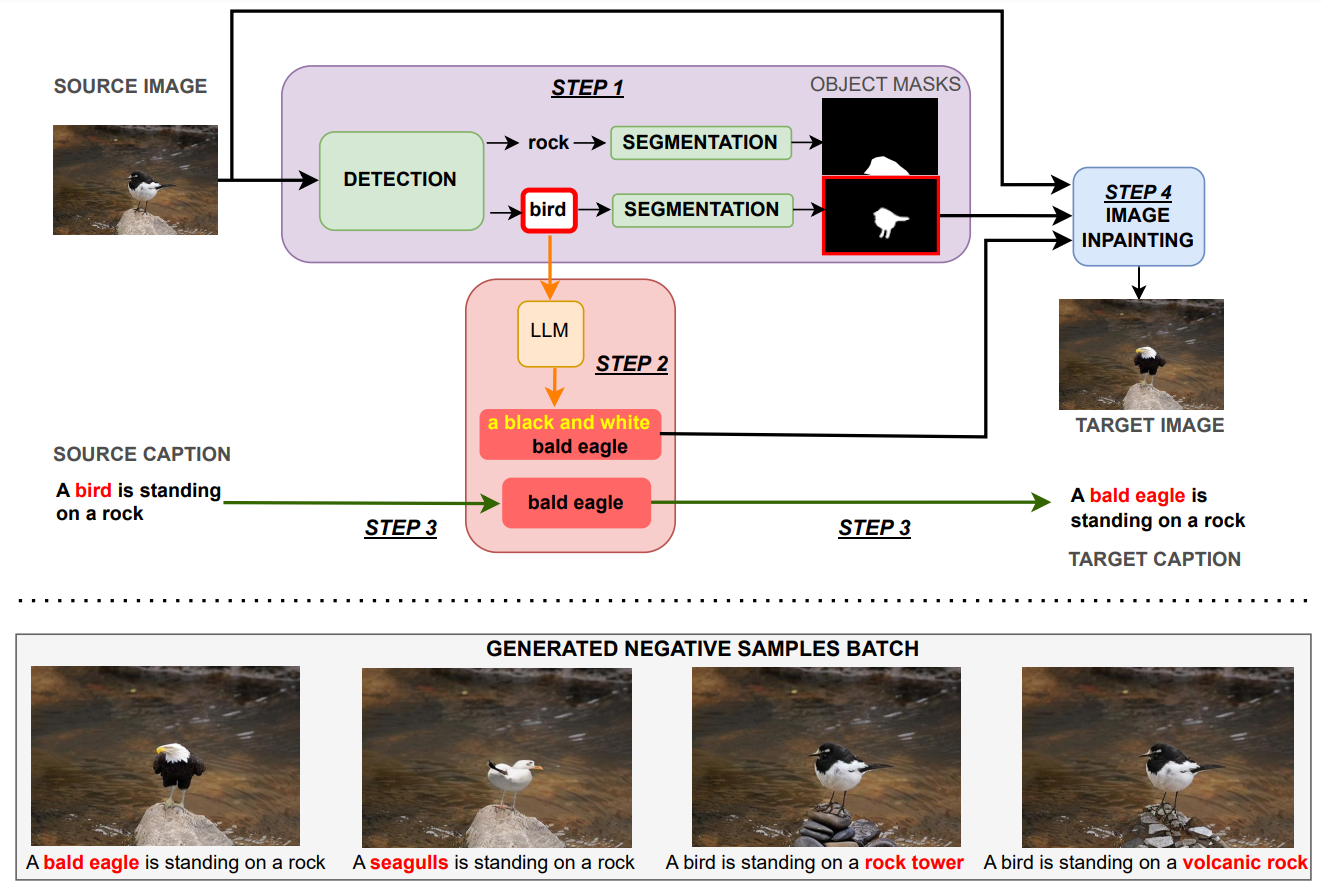
Robust Autonomous Vehicle Pursuit without Expert Steering Labels , In IEEE Robotics and Automation Letters (RA-L), volume 8, 2023. ([arXiv][code])
[] 
Learning vision based autonomous lateral vehicle control without supervision , In Applied Intelligence, Springer, 2023. ([paper][github])
Preprints
[] 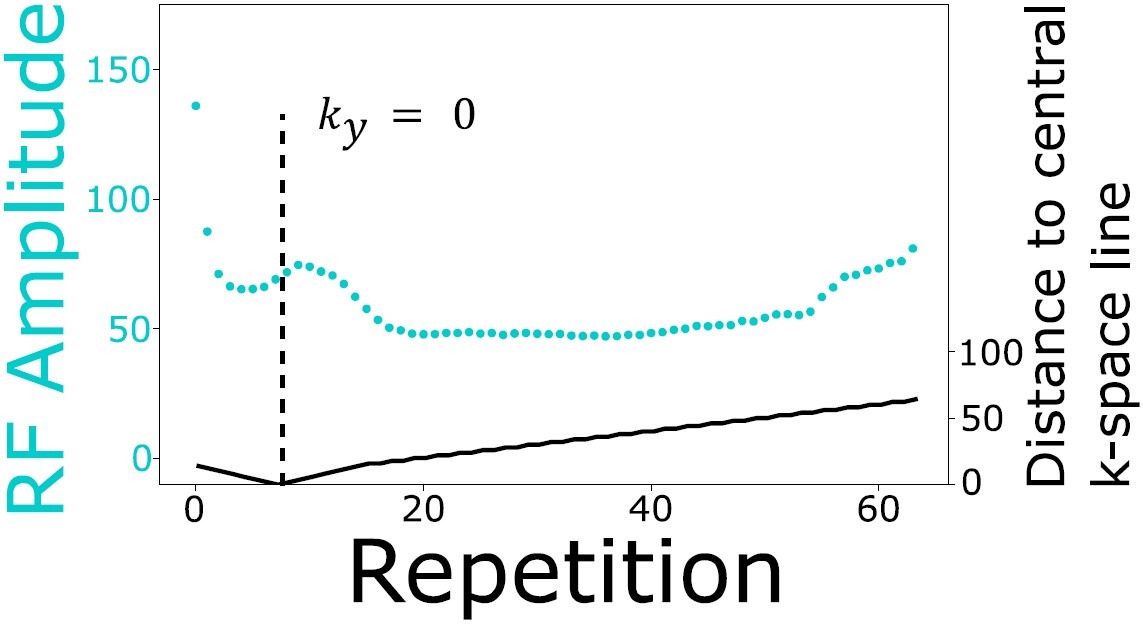
Joint MR sequence optimization beats pure neural network approaches for spin-echo MRI super-resolution , In arXiv preprint arXiv:2305.07524, 2023.
[] 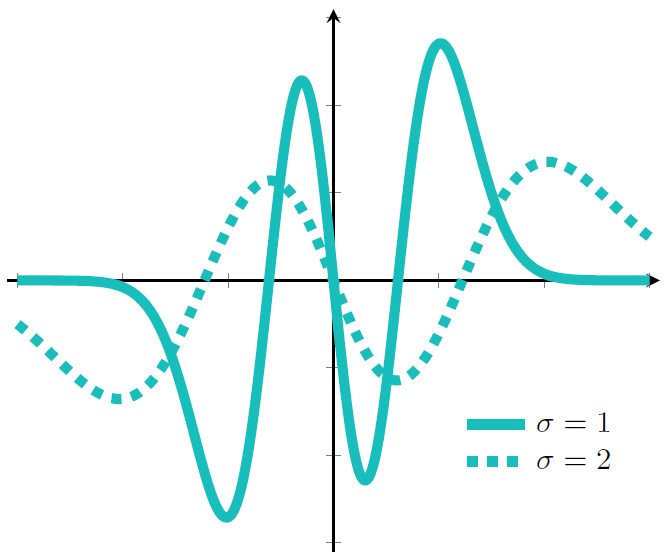
Scale-Equivariant Deep Learning for 3D Data , In arXiv preprint, 2023.
[] Quality Control at Your Fingertips: Quality-Aware Translation Models , In arXiv preprint, 2023.
Conference and Workshop Papers
[] 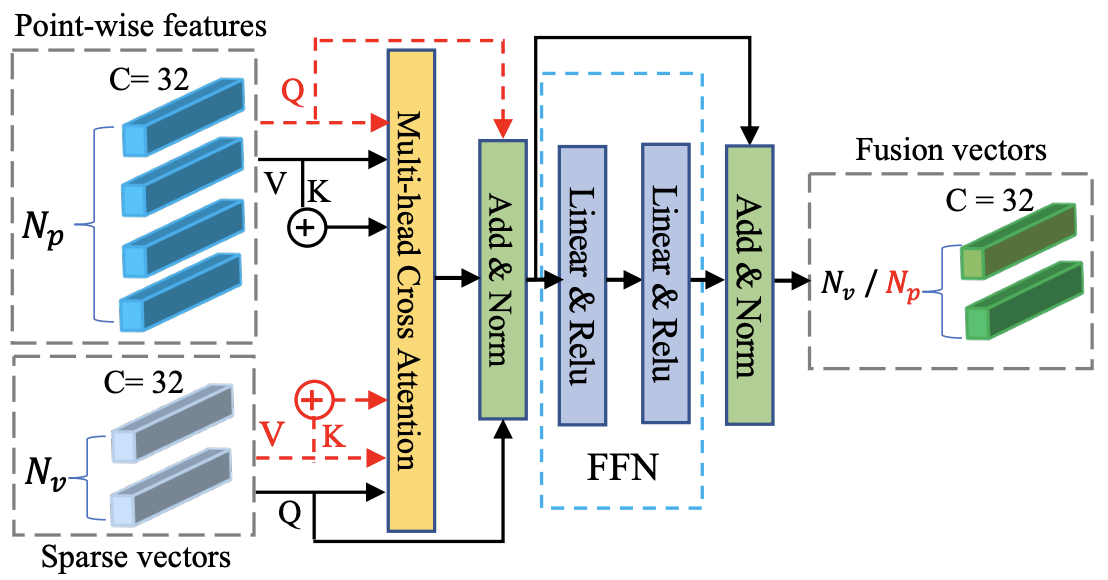
CASSPR: Cross Attention Single Scan Place Recognition , In IEEE International Conference on Computer Vision (ICCV), 2023. ([code])
[] 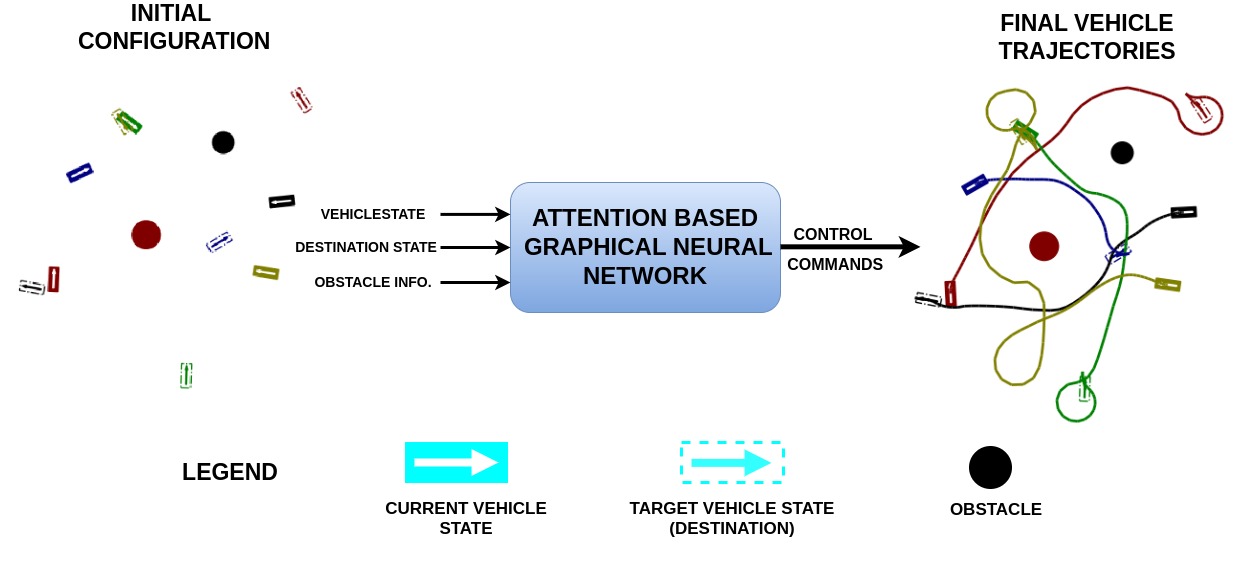
Multi Agent Navigation in Unconstrained Environments Using a Centralized Attention Based Graphical Neural Network Controller , In IEEE 26th International Conference on Intelligent Transportation Systems, 2023. ([project page][code])
[] 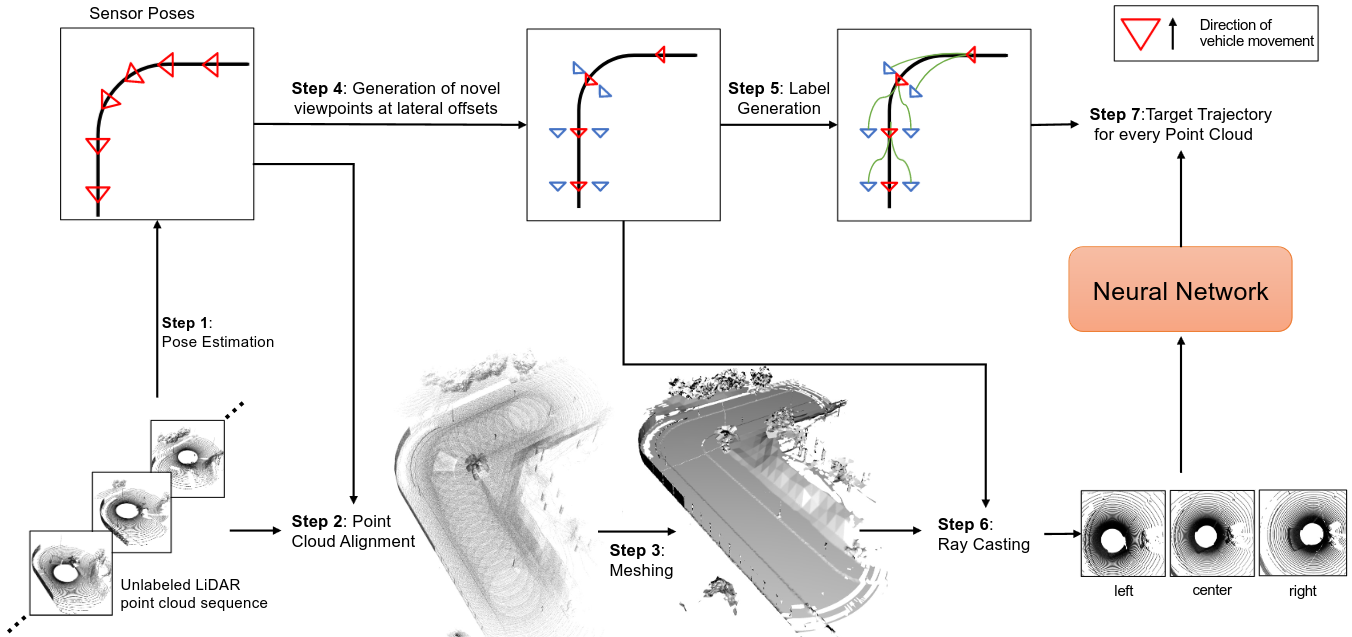
LiDAR View Synthesis for Robust Vehicle Navigation Without Expert Labels , In IEEE 26th International Conference on Intelligent Transportation Systems, 2023. ([project page][arxiv][code])
[] 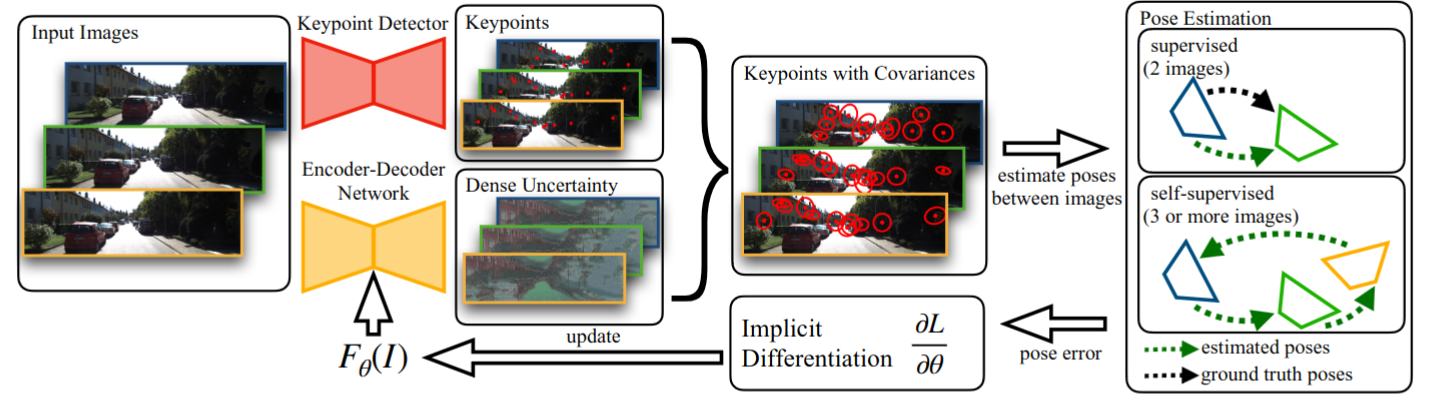
Learning Correspondence Uncertainty via Differentiable Nonlinear Least Squares , In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. ([project page])
[] 
GPT4MR: Exploring GPT-4 as an MR Sequence and Reconstruction Programming Assistant , In European Society for Magnetic Resonance in Medicine and Biology (ESMRMB) Annual Meeting, 2023.
Oral Presentation [] 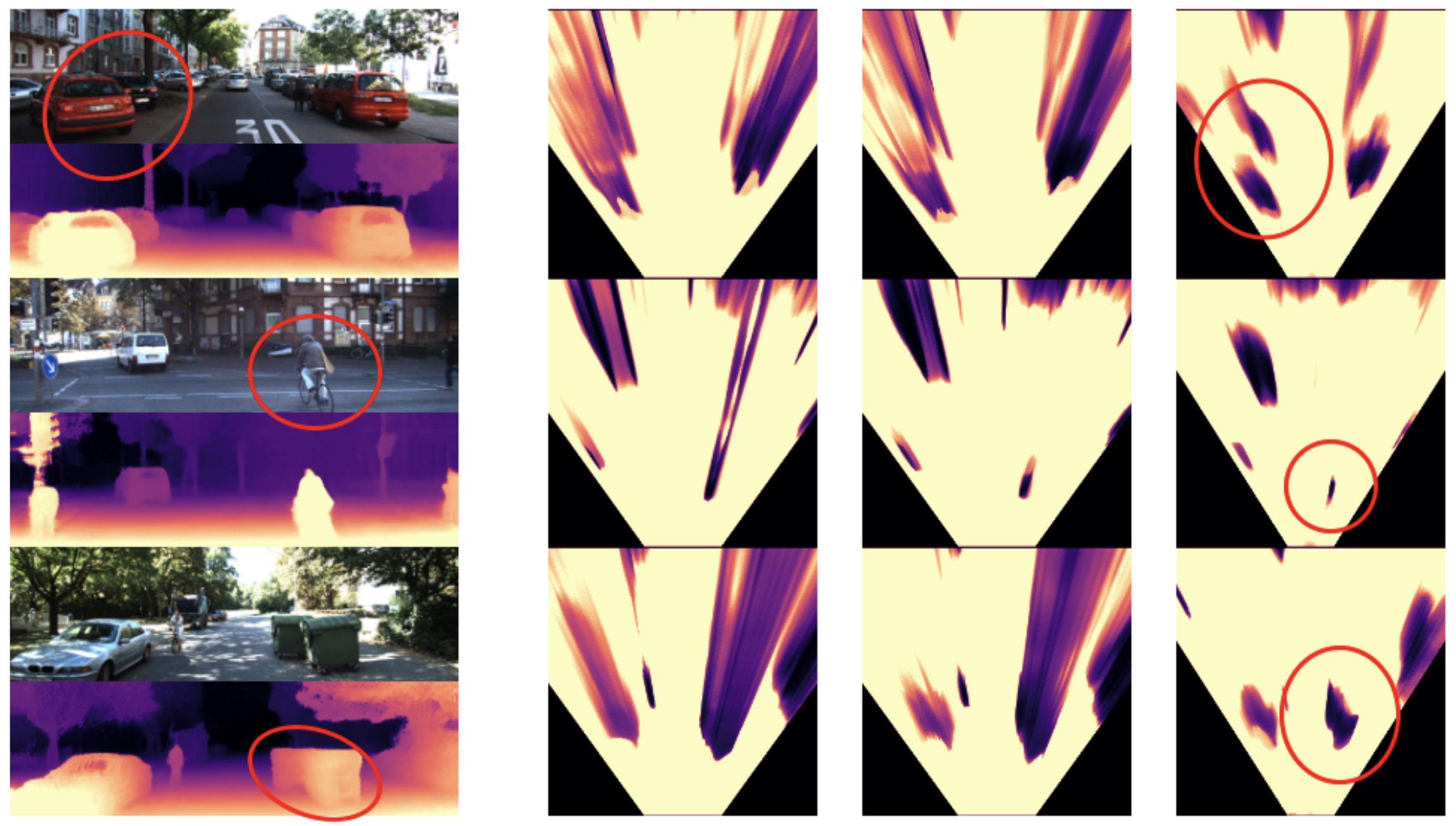
Behind the Scenes: Density Fields for Single View Reconstruction , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. ([project page])
[] Beyond In-Domain Scenarios: Robust Density-Aware Calibration , In Proceedings of the 40th International Conference on Machine Learning (ICML), 2023.
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2022
Journal Articles
[] 
Deep Learning in Attosecond Metrology , In Optics Express, OSA, volume 30, 2022.
Editor's Pick
Preprints
[] 
Challenger: Training with Attribution Maps , In arXiv preprint, 2022.
Conference and Workshop Papers
[] 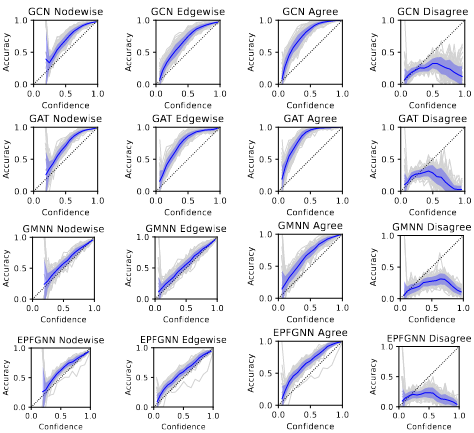
A Graph Is More Than Its Nodes: Towards Structured Uncertainty-Aware Learning on Graphs , In NeurIPS 2022 Workshop: New Frontiers in Graph Learning, 2022. ([code])
[] 
Deep Combinatorial Aggregation , In NeurIPS, 2022. ([code])
[] 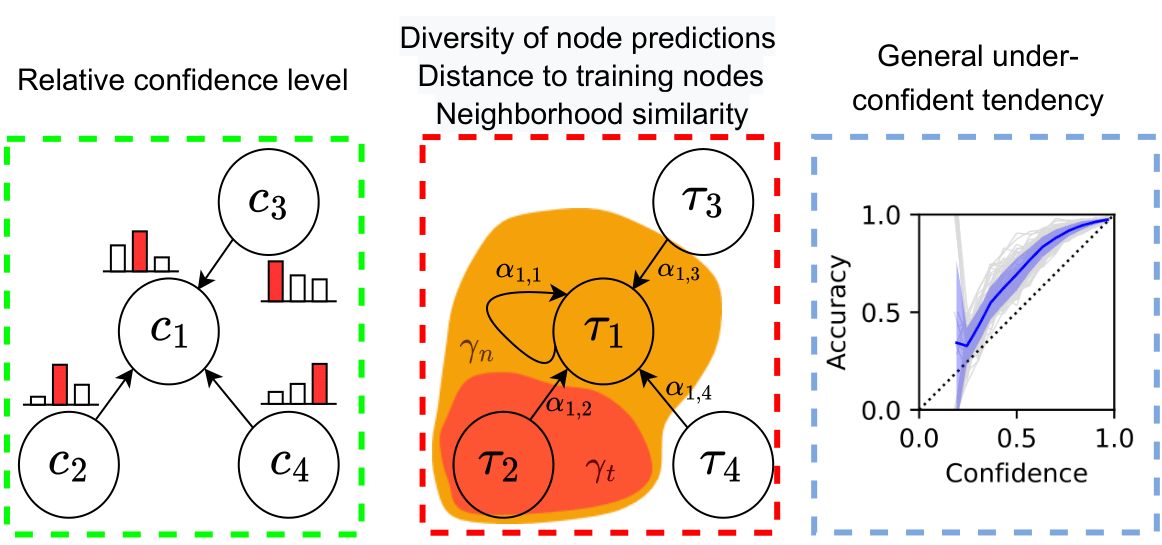
What Makes Graph Neural Networks Miscalibrated? , In NeurIPS, 2022. ([code])
[] 
Ventriloquist-Net: Leveraging Speech Cues for Emotive Talking Head Generation , In IEEE International Conference on Image Processing, 2022.
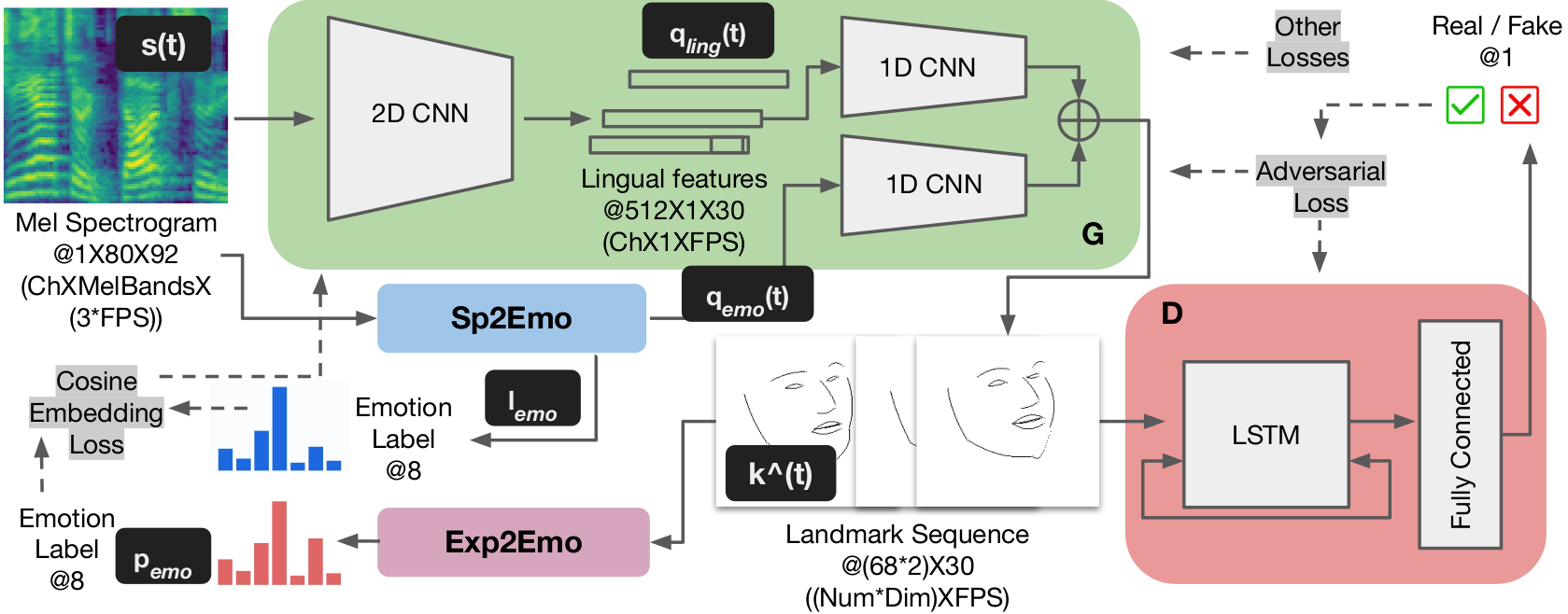
[] 
Biologically Inspired Neural Path Finding , In Brain Informatics, Springer International Publishing, 2022. ([code])
[] 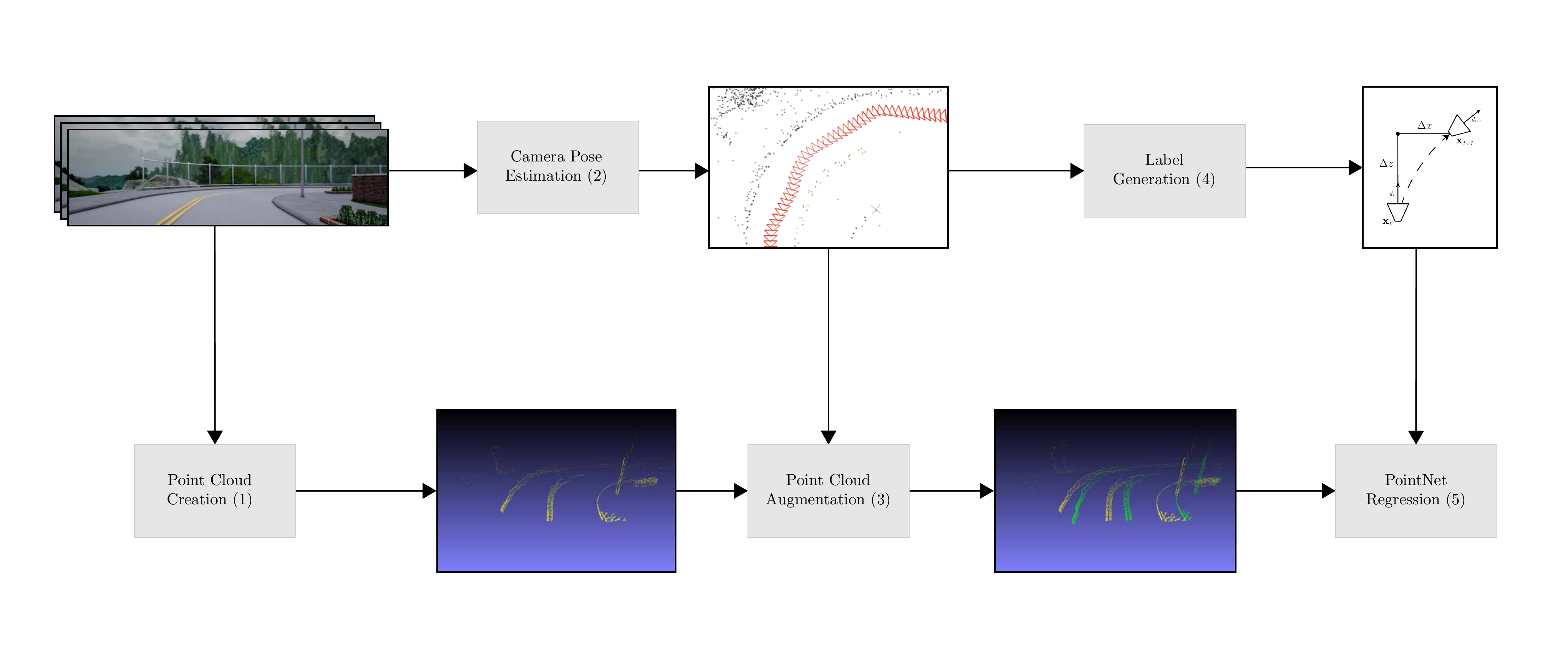
Lateral Ego-Vehicle Control Without Supervision Using Point Clouds , In Pattern Recognition and Artificial Intelligence, Springer International Publishing, 2022.
[] 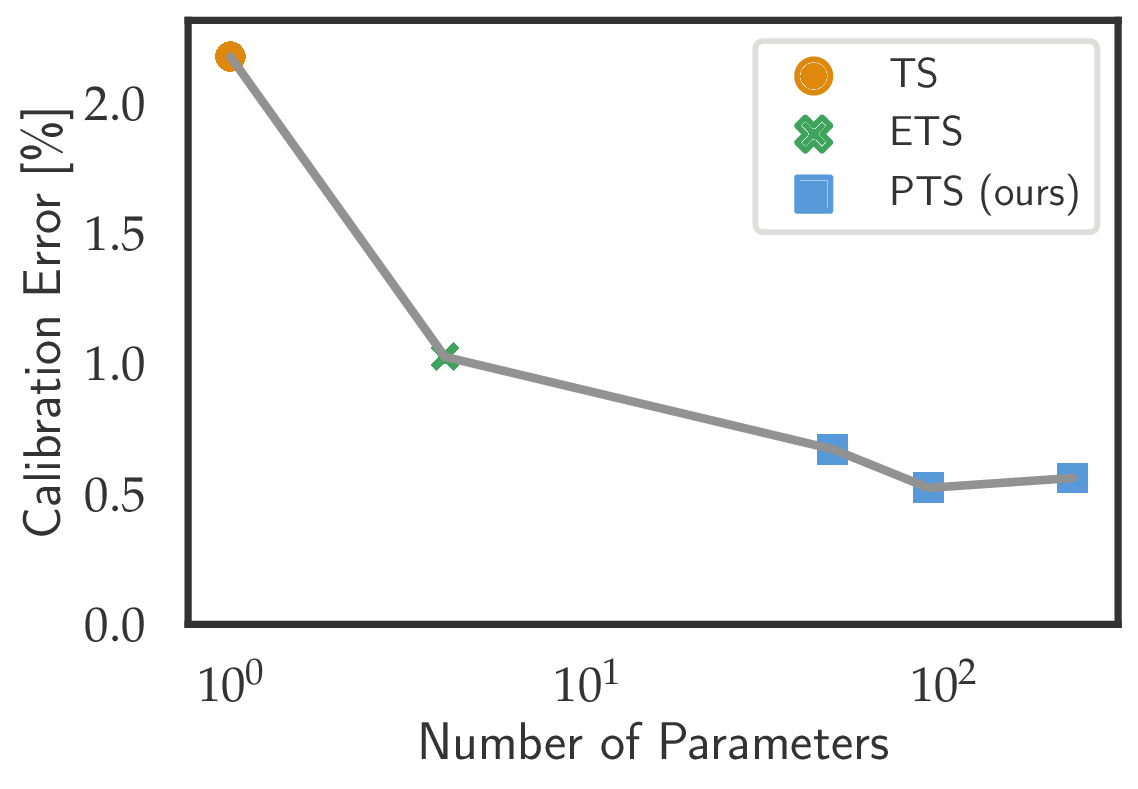
Parameterized Temperature Scaling for Boosting the Expressive Power in Post-Hoc Uncertainty Calibration , In European Conference on Computer Vision (ECCV), 2022.
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2021
Preprints
[] 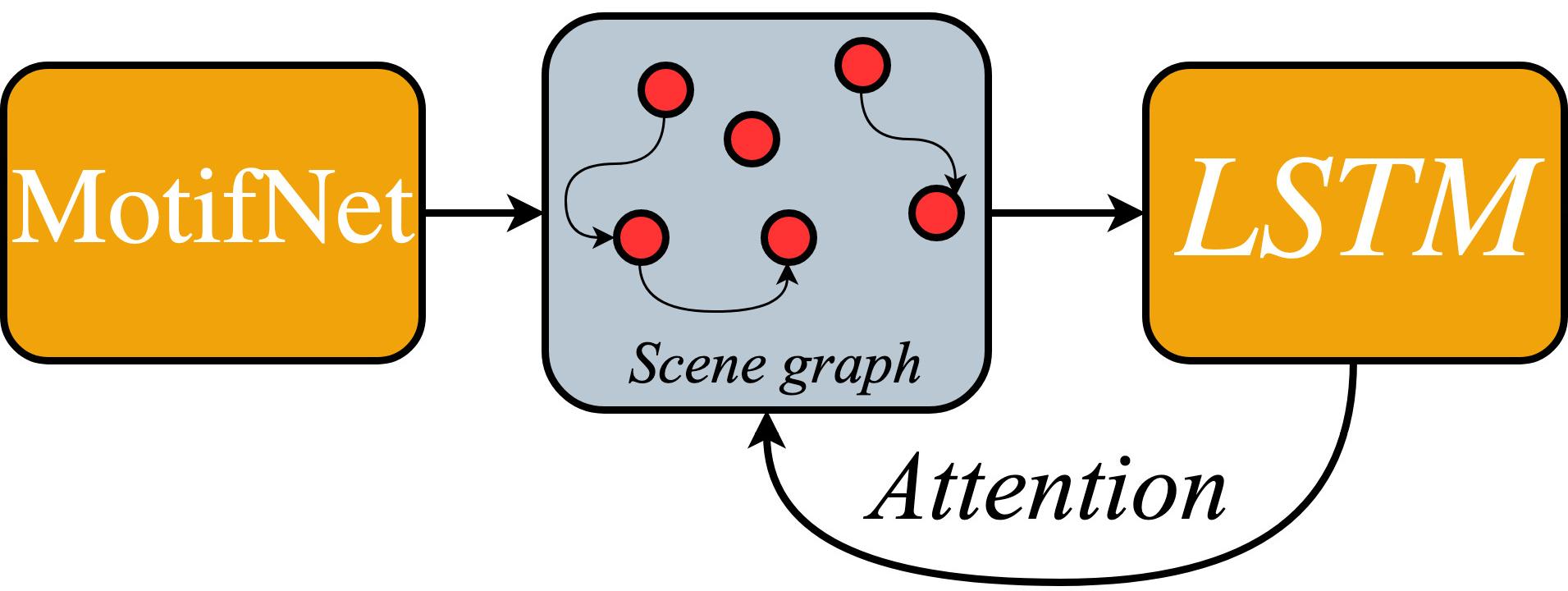
Scene Graph Generation for Better Image Captioning? , In arXiv preprint, 2021.
[] 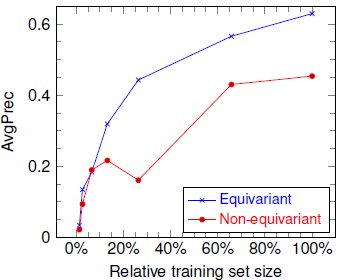
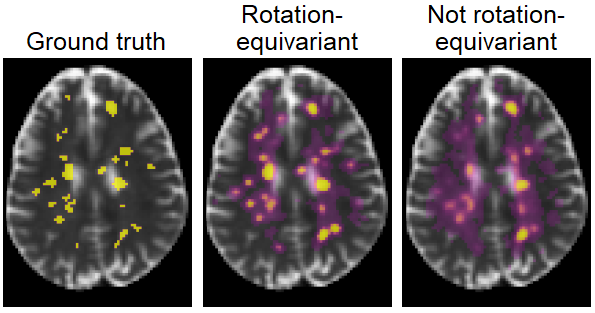
Rotation-Equivariant Deep Learning for Diffusion MRI , In arXiv preprint, 2021.
Conference and Workshop Papers
[] 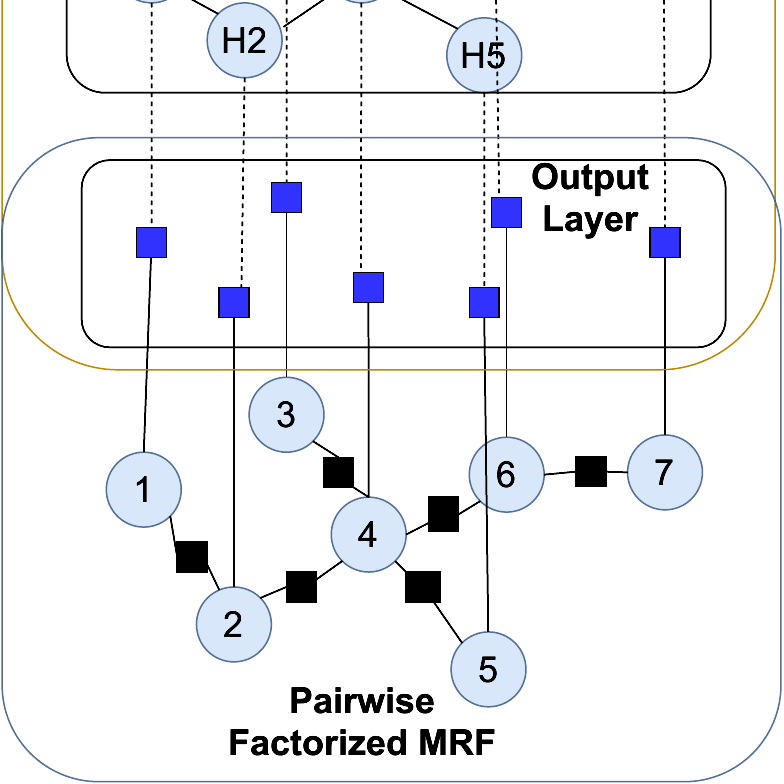
Explicit pairwise factorized graph neural network for semi-supervised node classification , In UAI, 2021. ([code])
[] 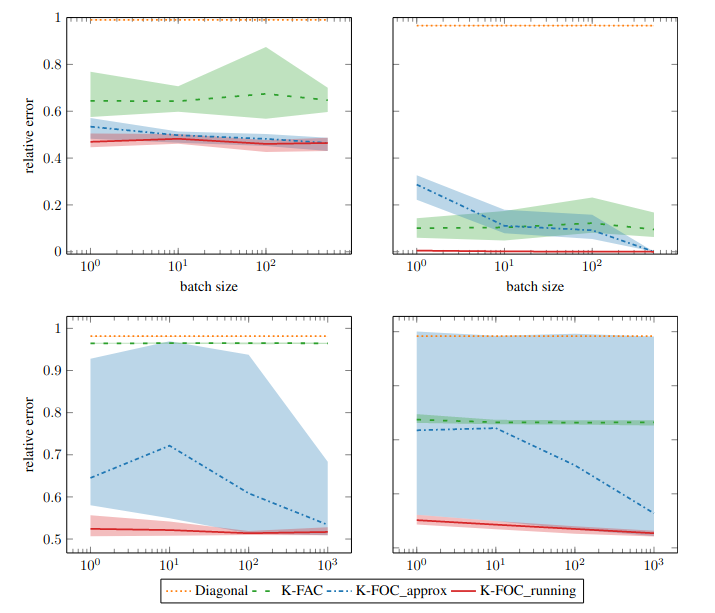
Kronecker-Factored Optimal Curvature , In Bayesian Deep Learning NeurIPS 2021 Workshop, 2021. ([poster])
[] 
Post-hoc Uncertainty Calibration for Domain Drift Scenarios , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
Oral Presentation [] 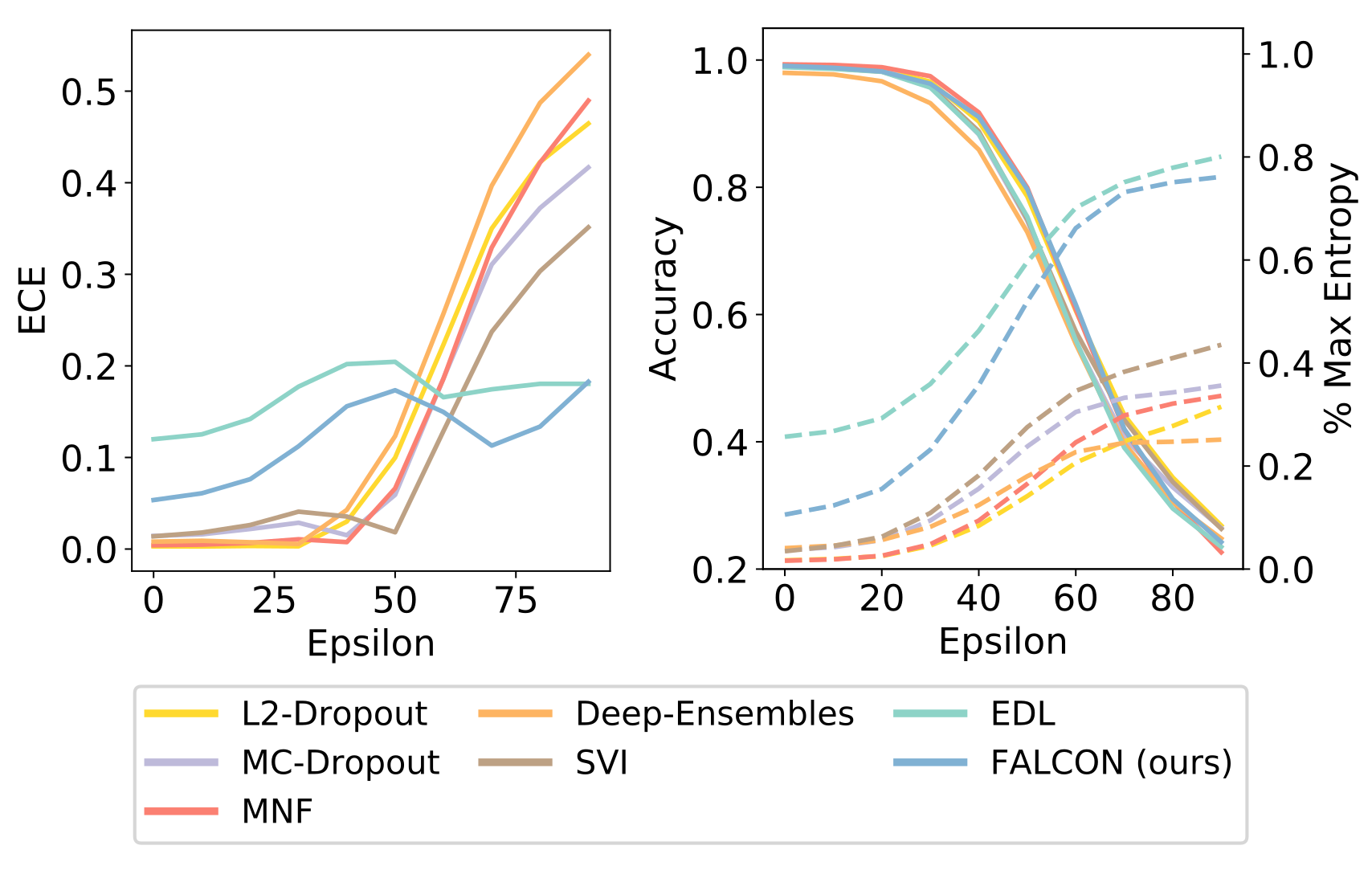
Towards Trustworthy Predictions from Deep Neural Networks with Fast Adversarial Calibration , In InThirty-FifthAAAIConferenceonArtificialIntelligence(AAAI-2021), 2021.
[] 
Vision-Based Mobile Robotics Obstacle Avoidance With Deep Reinforcement Learning , In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2021. ([arXiv])
[] 
SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. ([arxiv])
Oral Presentation [] 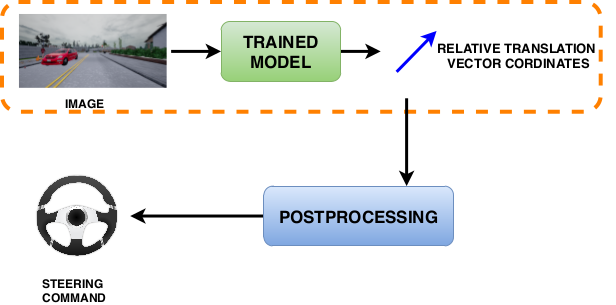
Self-Supervised Steering Angle Prediction for Vehicle Control Using Visual Odometry , In International Conference on Artificial Intelligence and Statistics (AISTATS), 2021. ([arXiv])
[] 
Rotation-Equivariant Deep Learning for Diffusion MRI (short version) , In International Society for Magnetic Resonance in Medicine (ISMRM) Annual Meeting, 2021.
[] 
MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. ([project page])
PhD Thesis
[] 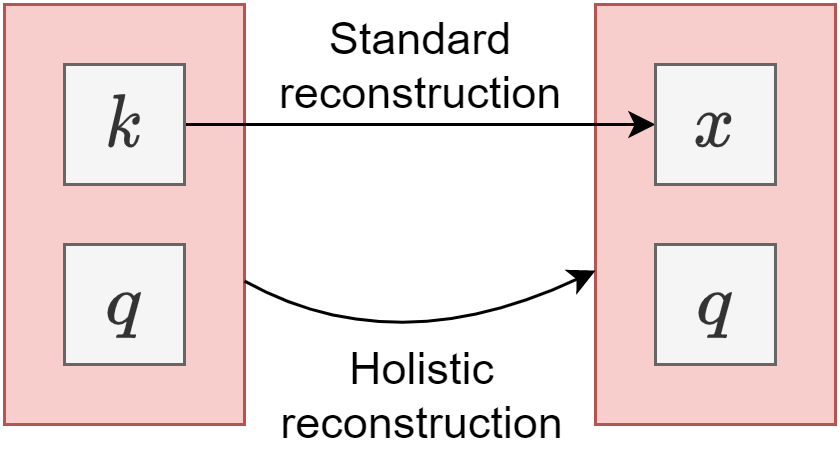
Deep learning and variational analysis for high-dimensional and geometric biomedical data , PhD thesis, Department of Informatics, Technical University of Munich, Germany, 2021.
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2020
Journal Articles
[] 
GN-Net: The Gauss-Newton Loss for Multi-Weather Relocalization , In IEEE Robotics and Automation Letters (RA-L), volume 5, 2020. ([arXiv][video][project page][supplementary])
Preprints
[] 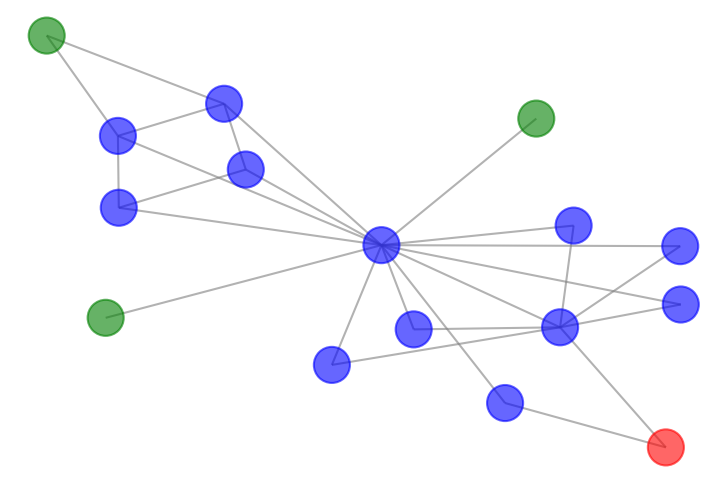
Neural Online Graph Exploration , In arXiv preprint arXiv:2012.03345, 2020. ([arxiv])
[] 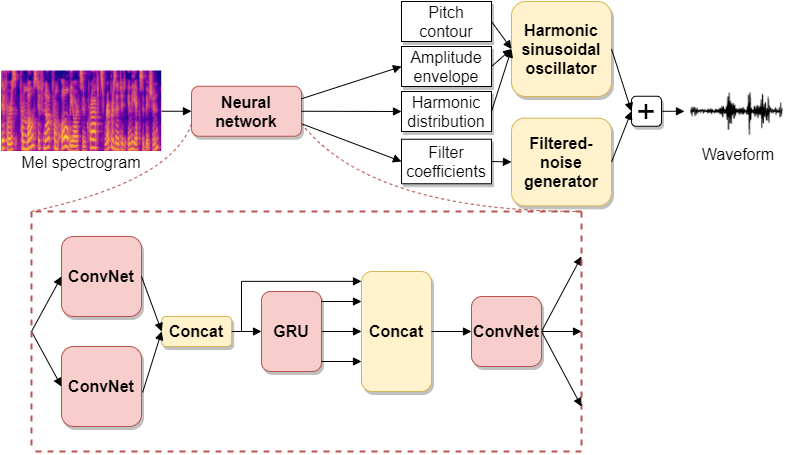
Speech Synthesis and Control Using Differentiable DSP , In arXiv preprint arXiv:2010.15084, 2020. ([listen to audio results])
[] 
Deep Learning for Virtual Screening: Five Reasons to Use ROC Cost Functions , In arXiv preprint arXiv:2007.07029, 2020.
Conference and Workshop Papers
[] 
LM-Reloc: Levenberg-Marquardt Based Direct Visual Relocalization , In International Conference on 3D Vision (3DV), 2020. ([arXiv][project page][video][supplementary][poster])
[] 
4Seasons: A Cross-Season Dataset for Multi-Weather SLAM in Autonomous Driving , In Proceedings of the German Conference on Pattern Recognition (GCPR), 2020. ([project page][arXiv][video])
[] 
Effective Version Space Reduction for Convolutional Neural Networks , In European Conference on Machine Learning and Data Mining (ECML-PKDD), 2020. ([arxiv])
[] 
D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Oral Presentation [] 
3D Deep Learning for Biological Function Prediction from Physical Fields , In International Conference on 3D Vision (3DV), 2020.
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2019
Journal Articles
[] 
Efficient Deep Network Architectures for Fast Chest X-Ray Tuberculosis Screening and Visualization , In Scientific Reports, volume 9, 2019.
Preprints
[] 
Deep Learning for 2D and 3D Rotatable Data: An Overview of Methods , In arXiv preprint arXiv:1910.14594, 2019.
[] 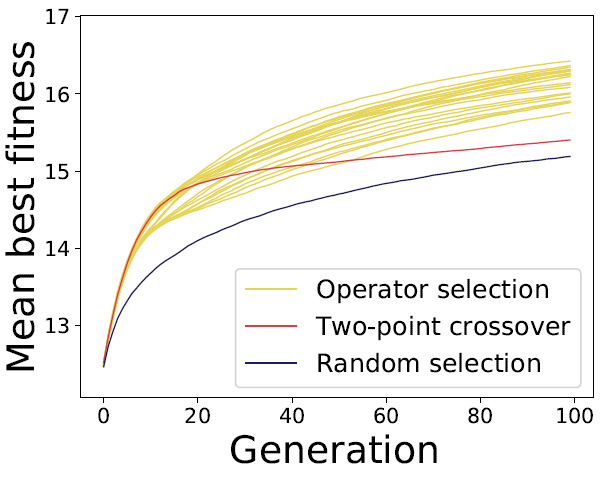
Learning to Evolve , In arXiv preprint arXiv:1905.03389, 2019.
Conference and Workshop Papers
[] 
Towards Generalizing Sensorimotor Control Across Weather Conditions , In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019. ([arXiv])
[] 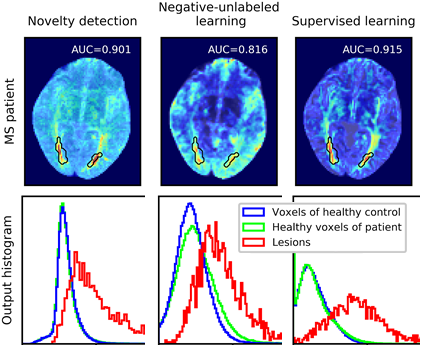
Negative-Unlabeled Learning for Diffusion MRI , In International Society for Magnetic Resonance in Medicine (ISMRM) Annual Meeting, 2019.
[] 
q-Space Novelty Detection with Variational Autoencoders , In MICCAI 2019 International Workshop on Computational Diffusion MRI, 2019.
Oral Presentation 2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2018
Journal Articles
[] 
What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation? , In , volume 41, 2018. (arxiv)
Preprints
[] 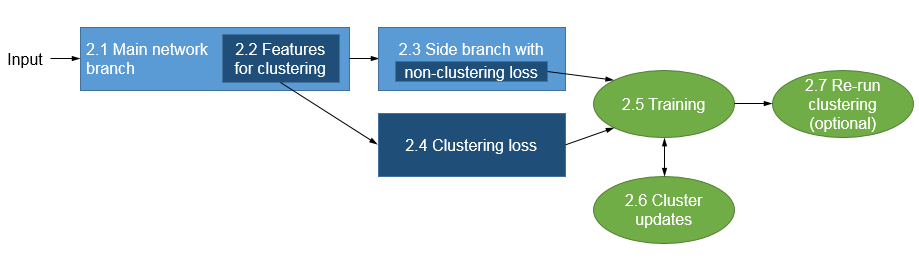
Clustering with Deep Learning: Taxonomy and New Methods , In arXiv preprint arXiv:1801.07648, 2018.
[] 
Precursor microRNA Identification Using Deep Convolutional Neural Networks , In bioRxiv preprint 414656, 2018. (bioRxiv:414656)
Conference and Workshop Papers
[] 
Modular Vehicle Control for Transferring Semantic Information Between Weather Conditions Using GANs , In Conference on Robot Learning (CoRL), 2018. ([arXiv][videos][poster])
[] 
Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry , In European Conference on Computer Vision (ECCV), 2018. ([arxiv],[supplementary],[project])
Oral Presentation [] 
Associative Deep Clustering - Training a Classification Network with no Labels , In Proc. of the German Conference on Pattern Recognition (GCPR), 2018.
[] 
q-Space Deep Learning for Alzheimer's Disease Diagnosis: Global Prediction and Weakly-Supervised Localization , In International Society for Magnetic Resonance in Medicine (ISMRM) Annual Meeting, 2018.
[] 
Deep Depth From Focus , In Asian Conference on Computer Vision (ACCV), 2018. ([arxiv], Deep Depth From Focus,[dataset])
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2017
Preprints
[] 
Regularization for Deep Learning: A Taxonomy , In arXiv preprint arXiv:1710.10686, 2017.
Conference and Workshop Papers
[] 
Associative Domain Adaptation , In IEEE International Conference on Computer Vision (ICCV), 2017. ([code] [PDF from CVF])
[] 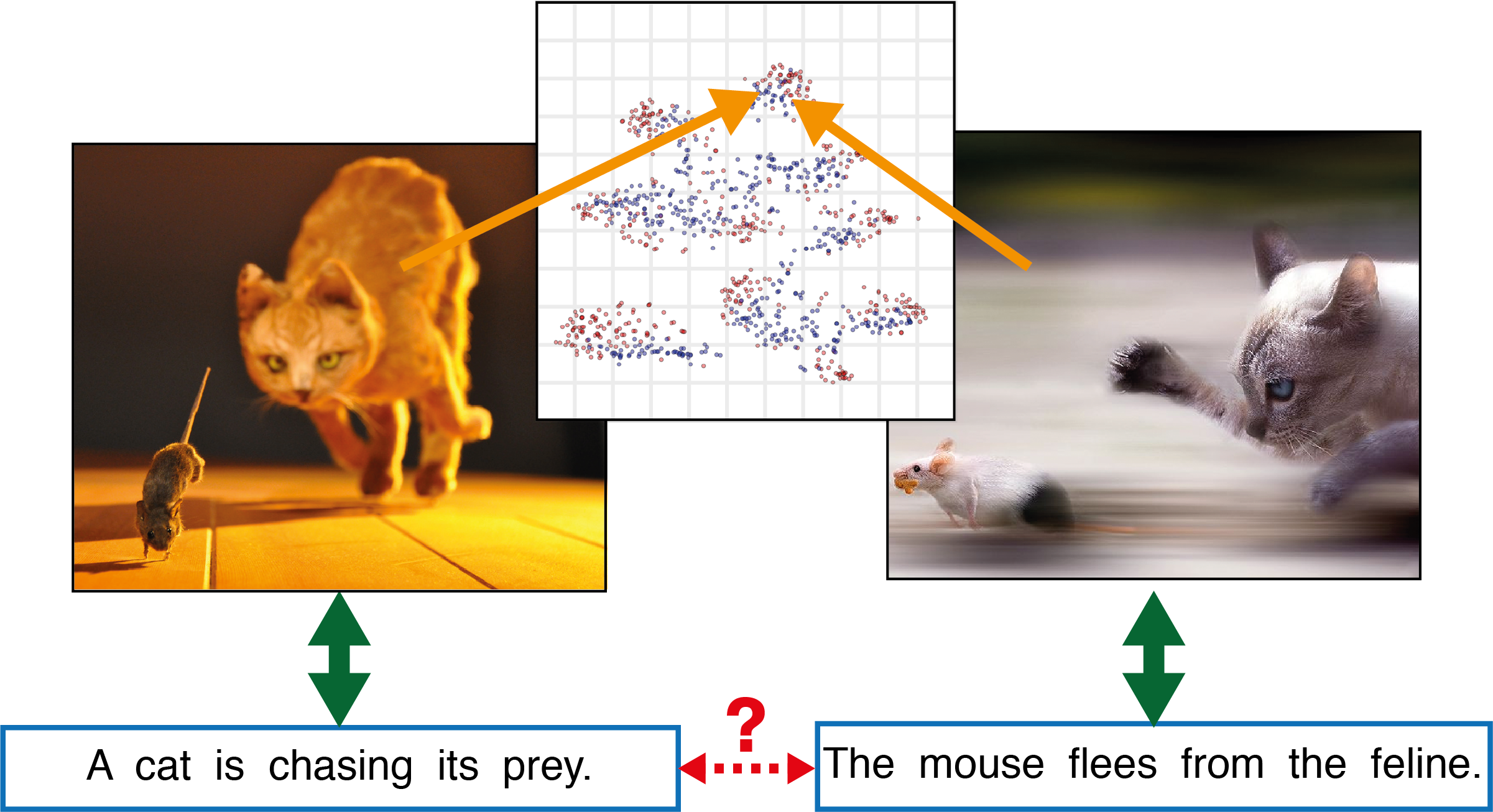
Better Text Understanding Through Image-To-Text Transfer , In arxiv:1705.08386, 2017.
[] 
One-Shot Video Object Segmentation , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[] 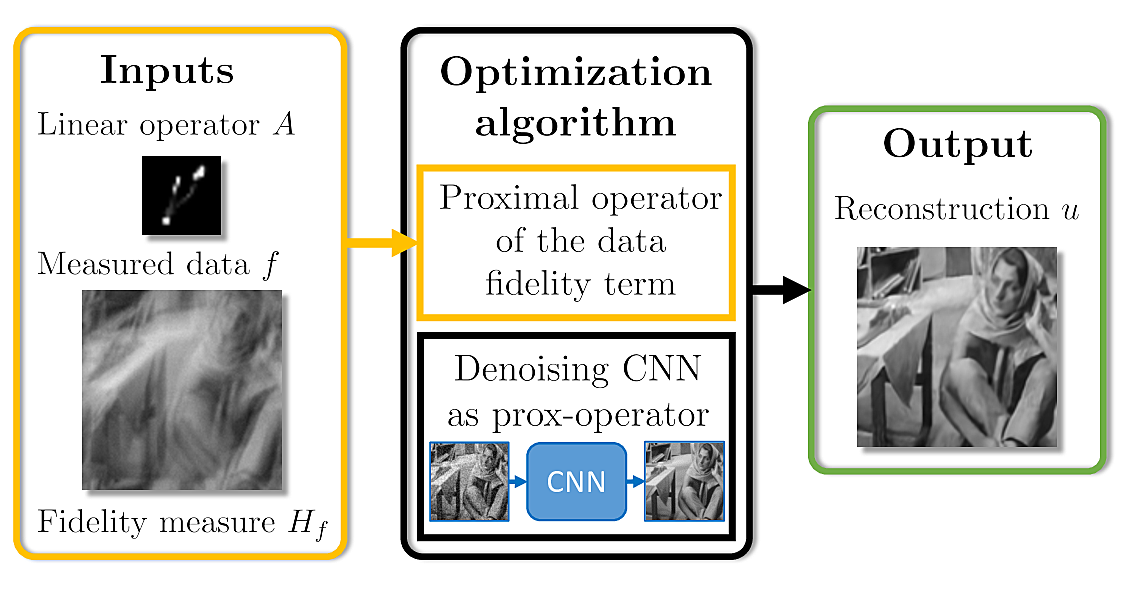
Learning Proximal Operators: Using Denoising Networks for Regularizing Inverse Imaging Problems , In IEEE International Conference on Computer Vision (ICCV), 2017. ([arxiv], [code])
[] 
Learning by Association - A versatile semi-supervised training method for neural networks , In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. ([code] [PDF from CVF])
[] Establishment of an interdisciplinary workflow of machine learning-based Radiomics in sarcoma patients , In 23. Jahrestagung der Deutschen Gesellschaft für Radioonkologie (DEGRO), 2017.
[] 
Image-based localization using LSTMs for structured feature correlation , In IEEE International Conference on Computer Vision (ICCV), 2017. ([arxiv])
2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2016
Journal Articles
[] 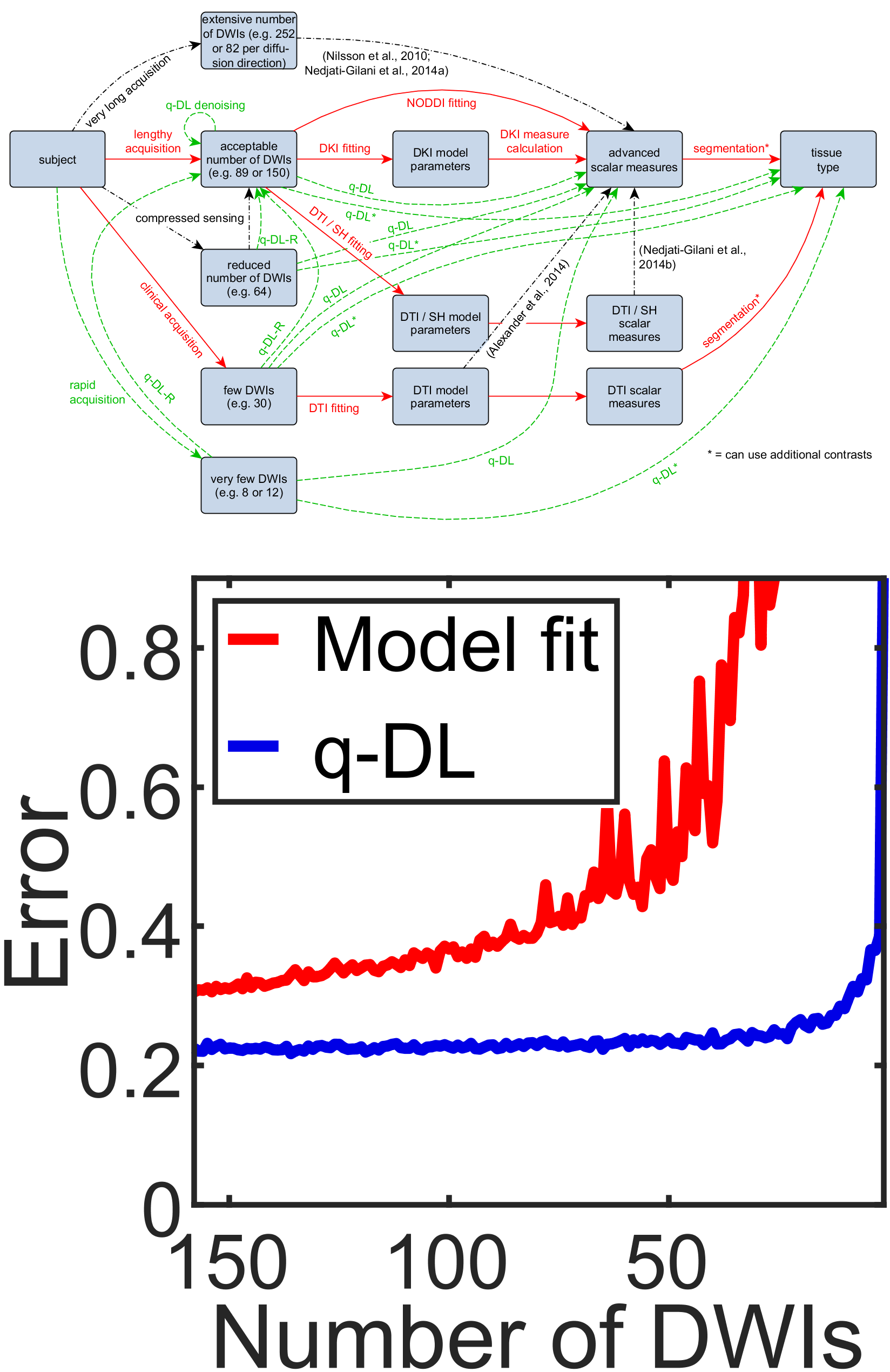
q-Space Deep Learning: Twelve-Fold Shorter and Model-Free Diffusion MRI Scans , In IEEE Transactions on Medical Imaging, volume 35, 2016. Special Issue on Deep Learning
Special Issue on Deep Learning
Conference and Workshop Papers
[] 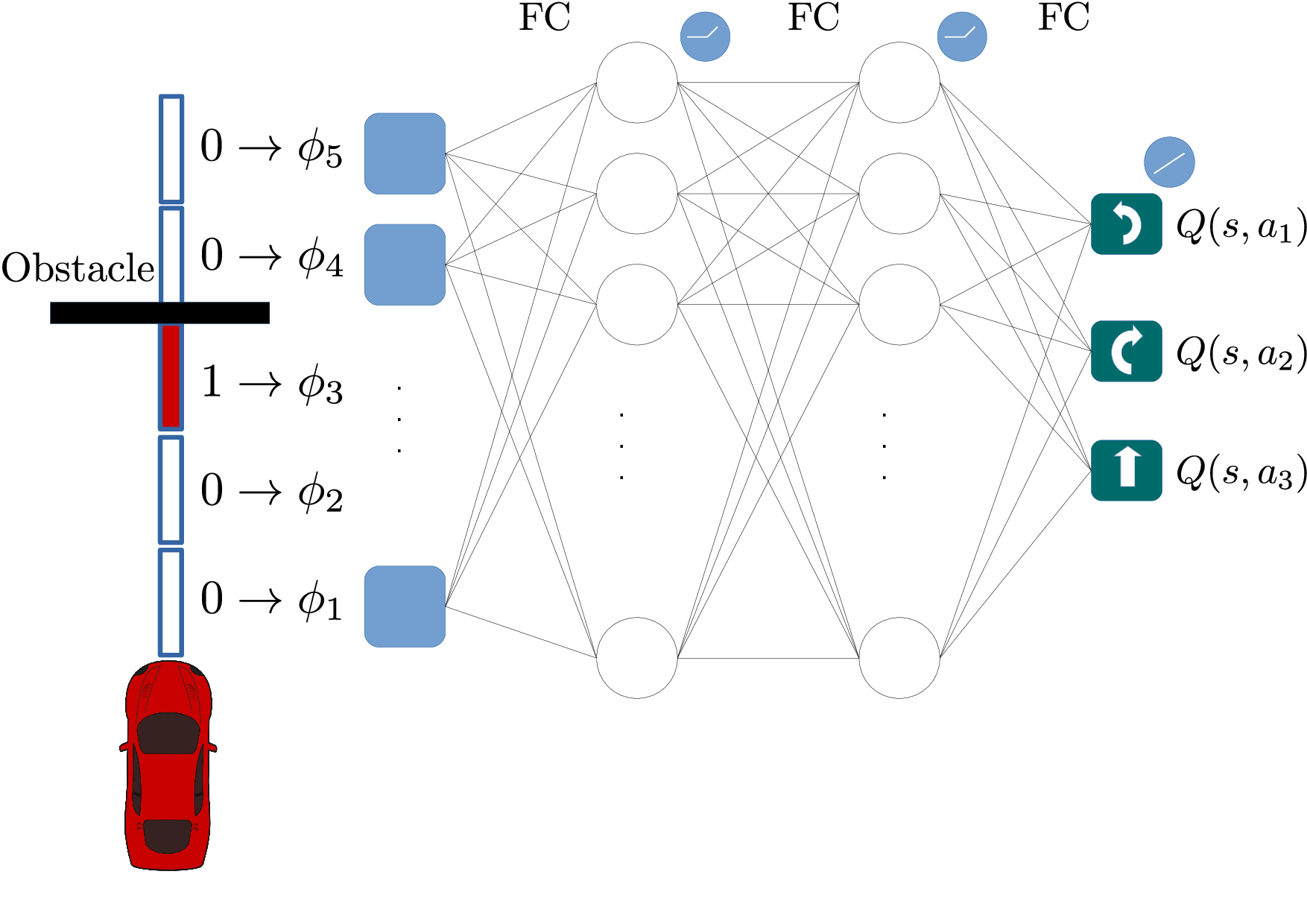
Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks , In , NIPS Workshops, 2016. ([arxiv])
[] 
FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture , In Asian Conference on Computer Vision, 2016. ([code])
[] 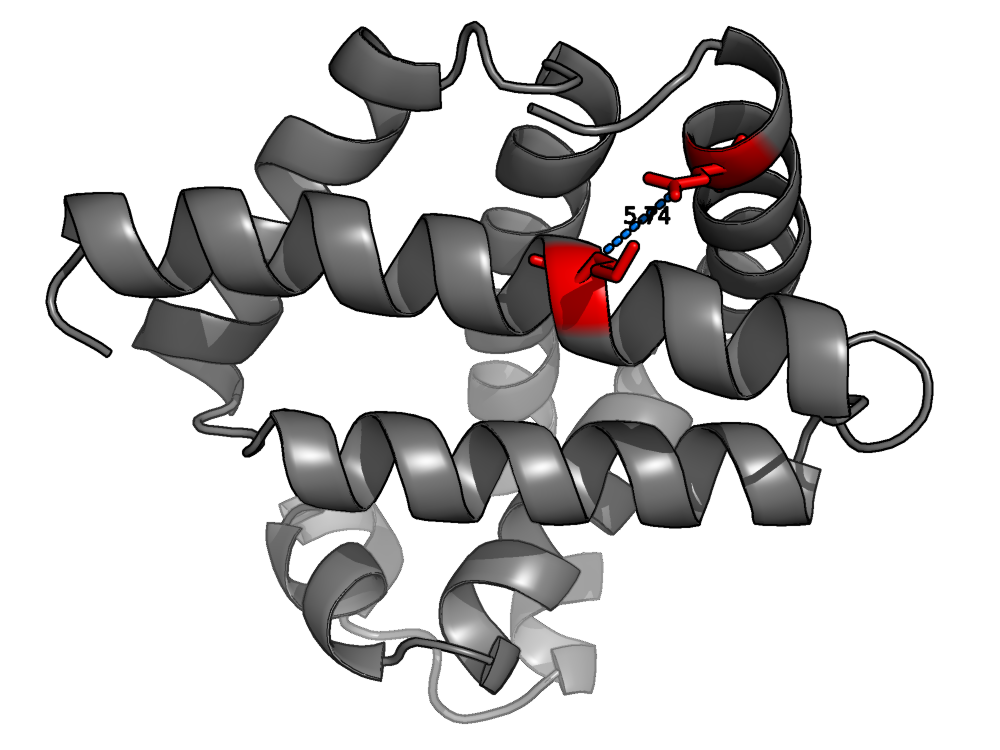
Protein Contact Prediction from Amino Acid Co-Evolution Using Convolutional Networks for Graph-Valued Images , In Annual Conference on Neural Information Processing Systems (NIPS), 2016. ([video])
Oral Presentation (acceptance rate: under 2%) 2024 | 2023 | 2022 | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015
2015
Conference and Workshop Papers
[] 
CAPTCHA Recognition with Active Deep Learning , In GCPR Workshop on New Challenges in Neural Computation, 2015. ([code])
[] 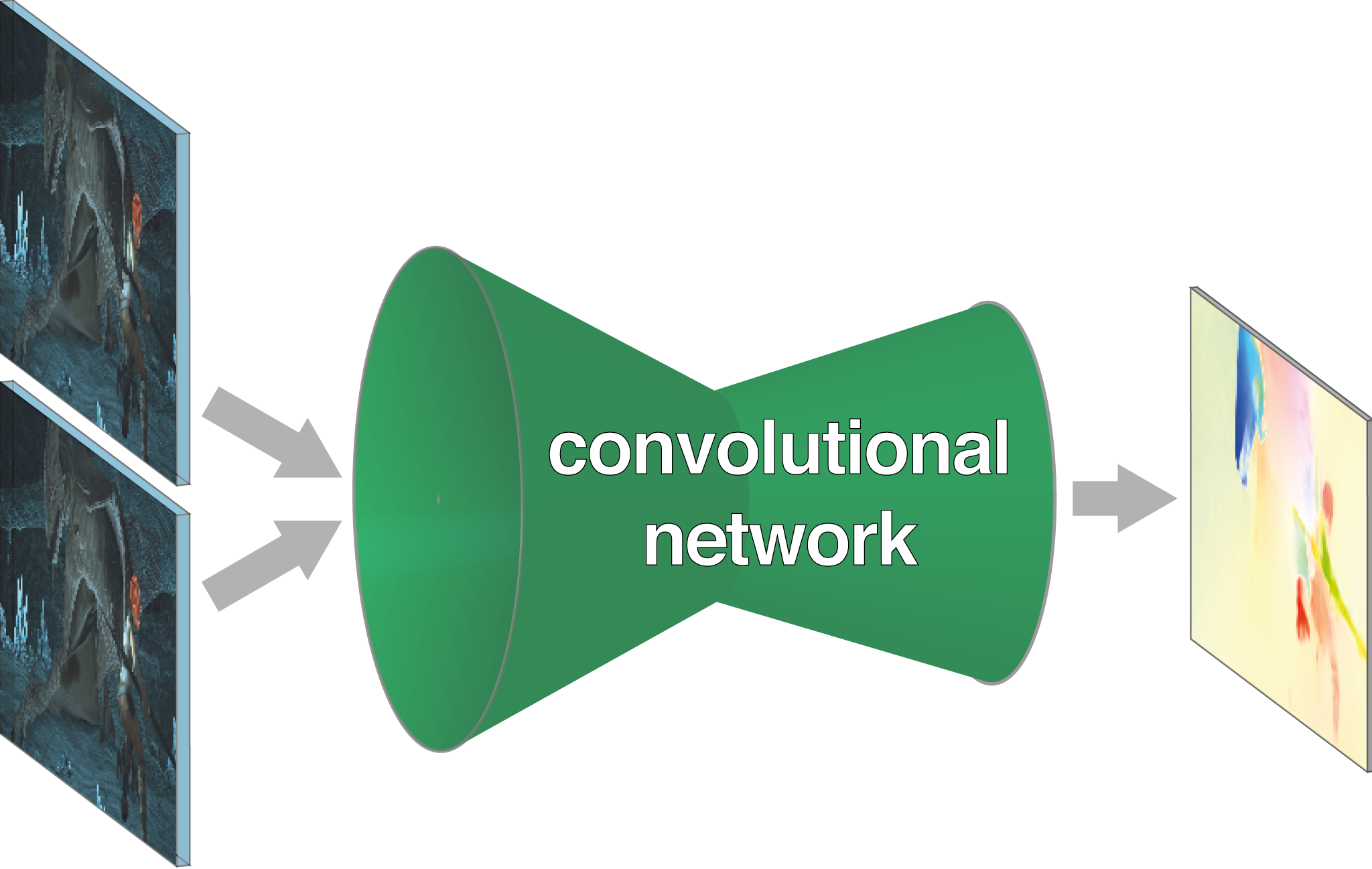
FlowNet: Learning Optical Flow with Convolutional Networks , In IEEE International Conference on Computer Vision (ICCV), 2015. ([video],[code])
[] 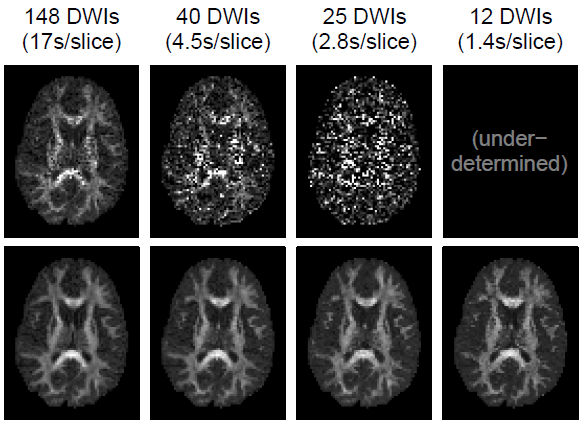
q-Space Deep Learning for Twelve-Fold Shorter and Model-Free Diffusion MRI Scans , In Medical Image Computing and Computer Assisted Intervention (MICCAI), 2015.